

스탠포드 인간중심AI연구소(HAI)가 4월 발표한 AI Index 2026은 제9차 연례보고서입니다.
이번 보고서의 메시지는 단 한 문장으로 압축됩니다.
“AI는 주변 시스템들이 적응할 수 있는 속도보다 빠르게 확장되고 있다.”
능력은 가속하는데 평가 체계, 거버넌스, 교육, 데이터 인프라는 따라잡지 못합니다.
대중화가 끝난 뒤의 세계, 이른바 ‘After Arrival’ 국면에서 격차가 본격적으로 벌어지고 있다는 진단입니다.
/출처: 스탠포드 HAI AI Index 2026 보고서
이 글은 보고서의 15대 Top Takeaways와 9개 챕터를 경제적 관점에서 해설하고, 한국 시장에 주는 시사점을 함께 정리하려고 합니다.

생성형 AI의 대중 채택, PC와 인터넷보다 빠른 3년 53%
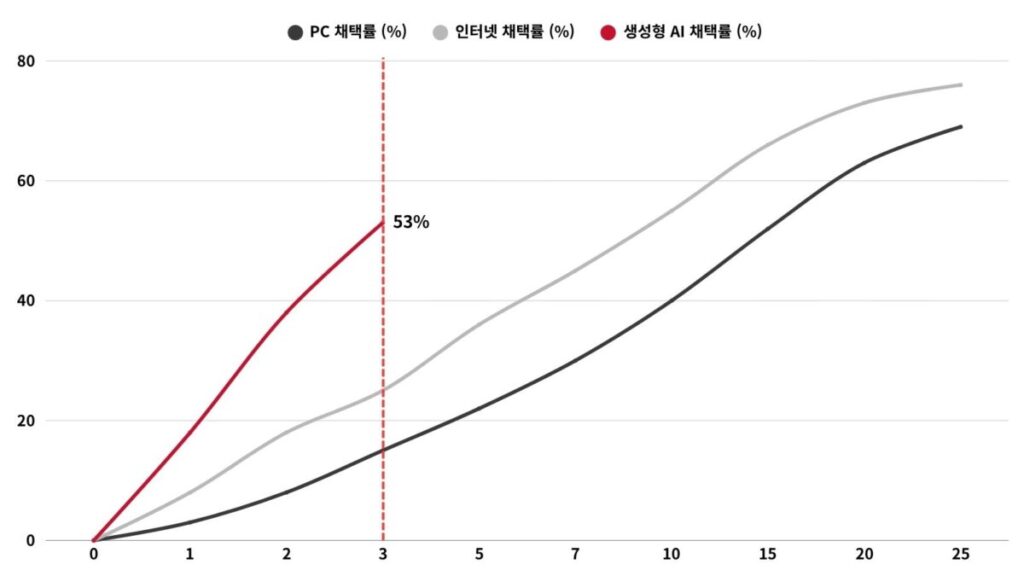
첫 번째 축은 확산 속도입니다.
생성형 AI는 대중시장 출시 후 단 3년 만에 인구 단위 채택률 53%에 도달했습니다.
개인용 컴퓨터와 인터넷보다 빠른 역사상 최단 기록입니다.
조직 단위 채택률은 2024년 78%에서 2025년 88%로 뛰었고, 생성형 AI가 최소 하나 이상의 업무 기능에 쓰이는 조직은 70%에 이릅니다.
미국 대학생 다섯 명 중 네 명이 이미 학교 과제에 생성형 AI를 활용합니다.
흥미로운 지점은 국가별 편차입니다.
채택률은 1인당 GDP와 강한 양의 상관관계를 보이지만 예외가 분명합니다.
싱가포르 61%, 아랍에미리트 54%는 소득 수준 대비 매우 높은 채택률을 기록했고, 반대로 AI 투자와 모델 개발의 주도국인 미국은 28.3%로 24위에 머물렀습니다.
한국은 25.9%에서 30.7%로 1년 사이 4.8%포인트 뛰어오르며 조사 대상 중 가장 큰 상승폭을 기록했고 순위도 25위에서 18위로 올라섰습니다.
미·중 모델 성능 격차의 사실상 소멸
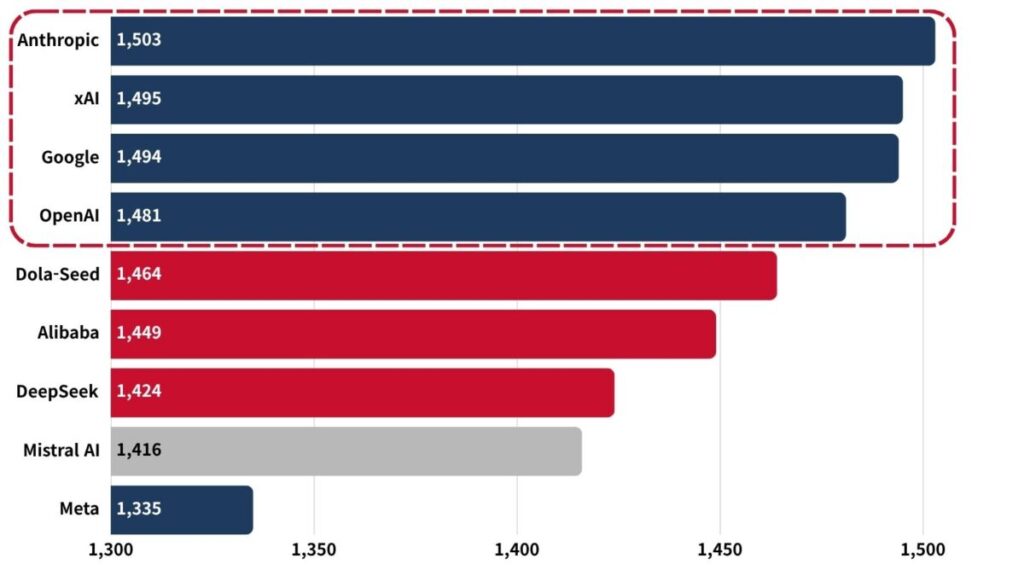
두 번째 축은 기술 경쟁 구도의 재편입니다.
2026년 3월 기준 Anthropic의 선도 모델이 중국 최상위 모델을 앞선 폭은 단 2.7%포인트입니다.
2025년 2월 DeepSeek-R1이 일시적으로 미국 1위를 추월한 이후 양국 모델은 선두 자리를 주고받고 있습니다.
Arena Elo 점수로 보면 Anthropic(1,503), xAI(1,495), Google(1,494), OpenAI(1,481), Alibaba(1,449), DeepSeek(1,424) 등 6개사가 25 Elo 포인트 이내로 밀집합니다.
상위권의 능력 차이가 사실상 사라졌다는 뜻입니다.
성능 격차가 닫히자 경쟁의 축은 모델 자체에서 물리적 인프라로 이동하고 있습니다.
2025년 주요 프론티어 모델의 90% 이상이 산업계에서 생산됐고, 그중 87건이 소수 빅테크에 집중됐습니다.
미국은 여전히 고성능 모델 생산 50건(중국 30건)과 고임팩트 특허에서 앞서지만, 중국은 논문 발표량·인용·특허 등록·산업용 로봇 설치 대수에서 세계 1위입니다.
2024년 전 세계 산업용 로봇 설치의 54%가 중국에서 이뤄졌습니다.
이 구도에서 한국은 독특한 위치를 차지합니다.
인구 대비 AI 특허 건수에서 세계 1위 – 규모가 작은 대신 밀도가 높은 생태계라는 신호입니다. 양적 경쟁에서는 미·중에 밀리지만 질적·집약적 혁신에서 자리를 잡고 있다는 평가가 가능합니다.
TSMC 단일 파운드리 의존과 미국 데이터센터 독주
인프라 측면의 쏠림은 더 극적입니다.
세계 선도 AI 칩의 대부분이 대만의 TSMC 한 곳에서 생산됩니다.
글로벌 AI 하드웨어 공급망 전체가 한 회사의 생산 역량에 묶여 있는 구조적 취약성입니다.
2025년 TSMC 미국 공장이 가동을 시작하며 지정학 리스크 완화를 위한 분산이 시작됐지만 단기 수급 구조 자체를 바꾸지는 못합니다.
데이터센터 분포도 극단적입니다.
미국은 5,427개의 데이터센터를 보유해 2위 국가의 10배 이상 규모이며 그 어느 나라보다 많은 에너지를 소비합니다.
글로벌 AI 연산 용량은 2022년 이후 매년 3.3배씩 성장해 2025년 H100 환산 1,710만 유닛에 도달했고, 엔비디아가 전체 연산의 60% 이상을 공급합니다.
하이퍼스케일러들의 자본 지출은 가속 중이어서 구글 단독으로 2025년 연간 CAPEX 1,500억 달러 이상을 집행한 것으로 보고됐습니다.
올림피아드 금메달과 시계 읽기 50% – Jagged Frontier
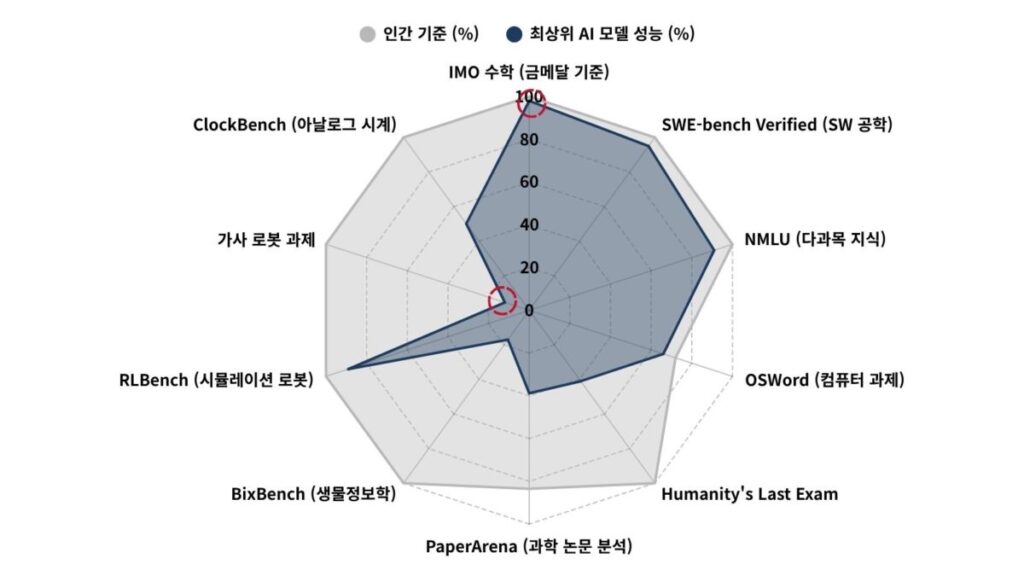
세 번째 축은 ‘Jagged Frontier(들쭉날쭉한 프런티어)’ 개념입니다.
Gemini Deep Think는 2025년 국제수학올림피아드에서 35점으로 금메달 기준을 돌파했습니다.
4.5시간 제한 내에 자연어만으로 끝까지 풀이를 수행한 결과입니다.
같은 모델들이 ClockBench의 아날로그 시계 읽기 과제에서는 정확도가 50.1%에 그쳤습니다.
인간 기준이 90.1%인 과제에서 말입니다.
연구자들이 ‘Jagged Intelligence’라고 명명한 이 불연속성은 배치 판단에 큰 영향을 미칩니다.
특정 과제에서는 박사급 성능을 내는 모델이 단순해 보이는 다른 과제에서는 아동 수준으로 실패합니다.
평균 성능 수치만으로는 실제 현장 배치 가능성을 판단할 수 없다는 뜻입니다.
에이전트 영역에서도 비슷한 양상이 나타납니다.
실제 운영체제에서 컴퓨터 작업을 수행하는 에이전트의 OSWorld 정확도는 약 12%에서 66.3%로 급등해 인간 성능과 6%포인트 차이까지 좁혀졌습니다.
그러나 구조화된 벤치마크에서 여전히 3회 중 1회는 실패합니다.
로봇 분야는 간극이 더 뚜렷합니다.
실험실 기반 RLBench 시뮬레이션에서는 89.4% 성공률을 기록하지만 실제 가정 환경에서의 가사 과제 성공률은 12%에 불과합니다.
시뮬레이션과 현실의 간극이 여전히 크다는 의미입니다.
예외는 자율주행입니다.
Waymo는 미국 5개 도시에서 주간 약 45만 회 운행에 도달했고, 중국 Apollo Go는 1,100만 회 완전 무인 탑승을 기록하며 전년 대비 175% 성장했습니다.
2025년 글로벌 기업 AI 투자 5,816억 달러 – 전년 대비 130% 증가
경제 수치로 넘어가면 이야기는 더 극적입니다.
2025년 글로벌 기업 AI 투자 총액은 M&A·지분 투자·민간 투자·IPO를 합쳐 5,816억 9천만 달러에 달했습니다.
전년 대비 129.9% 증가입니다.
이 중 민간 투자가 3,446억 6천만 달러로 가장 큰 비중(127.5% 성장)을 차지했고, 생성형 AI 단독 민간 투자는 1,708억 7천만 달러로 전년 대비 200% 이상 성장하며 전체 민간 AI 자금의 거의 절반을 차지했습니다.
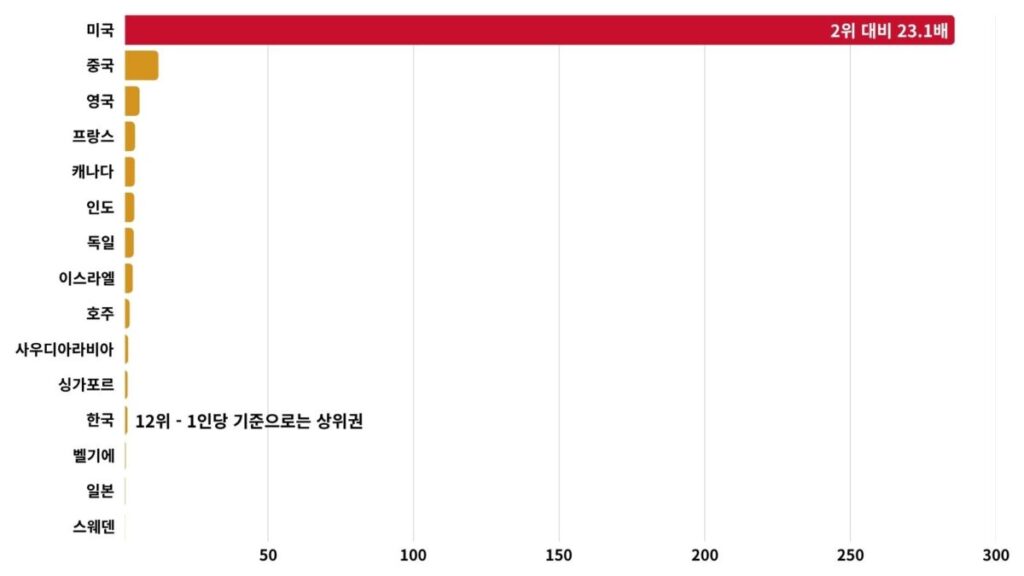
국가별 격차는 숫자 그 자체가 충격입니다.
2025년 미국 민간 AI 투자액은 2,858억 8천만 달러. 2위인 중국(124억 1천만 달러)의 23.1배, 3위 영국(59억 달러)의 48.5배입니다.
신규 펀딩 받은 AI 기업 수도 미국 1,953개로 2위 영국(172개)의 10배 이상입니다.
다만 보고서는 중국의 정부 유도 자금(2000~2023년 약 1,840억 달러 추정)을 감안하면 실제 국가 전체 지원 규모 격차는 훨씬 좁다는 점을 명시합니다.
민간 투자 수치만으로 국가 간 AI 역량을 비교하는 관행의 한계를 지적한 셈입니다.
미국 내부의 지역 집중도 극심합니다.
캘리포니아 한 주가 2,180억 달러로 미국 전체의 75% 이상을 차지했고, 콜로라도(190억 달러), 뉴욕(130억 달러), 플로리다(60억 달러)가 뒤를 이었습니다.
미국의 절반 이상 주는 1억 달러 미만을 받았고 사우스다코타·오클라호마·아칸소·웨스트버지니아는 아예 집계된 투자가 없었습니다.
10억 달러 이상의 대형 펀딩 이벤트는 2024년 15건에서 2025년 28건으로 늘었고, 평균 투자 규모도 전년 대비 46% 증가한 6,650만 달러에 이릅니다.
돈은 더 많이 흐르지만, 더 적은 수의 거래에 집중되고 있다는 뜻입니다.
프론티어 AI 기업들의 매출은 전례 없는 속도로 확장 중입니다.
OpenAI의 연환산 매출은 250억 달러, Anthropic은 190억 달러, xAI 4억 2,800만 달러, Mistral AI 4억 달러 수준으로 보고됩니다.
연산 비용도 같은 곡선을 그립니다.
OpenAI의 연간 컴퓨트 지출은 2022년 15억 달러에서 2025년 163억 달러로 치솟았고, Anthropic 역시 2024년 28억 달러에서 2025년 83억 달러로 급증했습니다.
미국 소비자 잉여 1,720억 달러 – 공식 GDP에 잡히지 않는 가치

투자·매출·비용이 공급 측 지표라면, 소비자 잉여는 수요 측 지표입니다.
스탠포드 브린욜프슨 교수팀의 온라인 선택 실험(2025년 N=1,400, 2026년 초 N=2,000)은 미국 소비자가 생성형 AI 도구에서 얻는 연간 가치를 2026년 초 기준 1,720억 달러로 추정했습니다.
1년 전 1,120억 달러에서 54% 증가한 수치입니다.
생성형 AI 사용자 1인당 평균 가치는 98달러에서 125달러로 27% 상승, 중위값은 3.4달러에서 11.4달러로 3배 뛰었습니다.
핵심은 ‘무료의 역설’입니다.
대부분의 생성형 AI 도구는 무료거나 거의 무료입니다.
이 때문에 GDP 통계에는 거의 잡히지 않습니다.
소비자 잉여는 동 시기 미국 생성형 AI 매출 추정치를 훨씬 상회합니다.
기술이 만드는 사회적 수익(social return)이 생산자가 포착하는 민간 수익(private return)을 압도하는 구조입니다.
이는 노드하우스(2004)가 역사적 혁신들에서 발견한 패턴과 일치합니다.
생산성과 고용의 이원화 – 청년 개발자 20% 고용 감소
노동시장 지표는 낙관론과 경계심을 동시에 요구합니다.
마이크로 레벨 실증연구는 AI 도입이 특정 과제에서 측정 가능한 생산성 향상을 가져온다는 점을 일관되게 보여줍니다.
고객지원 상담원이 대화형 AI 어시스턴트를 사용하면 시간당 해결 건수가 14~15% 증가하고, GitHub Copilot을 쓰는 소프트웨어 개발자는 PR 완료량이 26% 늘어납니다.
마케팅 팀에 멀티모달 AI를 도입하면 1인당 산출량이 50% 증가한다는 연구도 있습니다.
여러 연구에서 공통적으로 나타나는 패턴은 ‘경험이 적은 작업자일수록 수혜가 크다’는 점입니다.
매크로 레벨 증거는 초기적이지만 축적되고 있습니다.
유럽 12,000개 기업 연구는 AI 도입이 노동생산성을 4% 끌어올리며 훈련 투자 1%포인트당 추가로 5.9%포인트의 생산성 이득이 있다고 보고했습니다.
미국은 2025년 노동생산성 증가율이 2.7%로, 직전 10년 평균(1.4%)의 거의 두 배를 기록했습니다.
OECD 분석은 G7 10년 호라이즌에서 생산성 +1.4%, 산출 +0.8%, 고용 -0.7%의 순효과를 시사합니다.
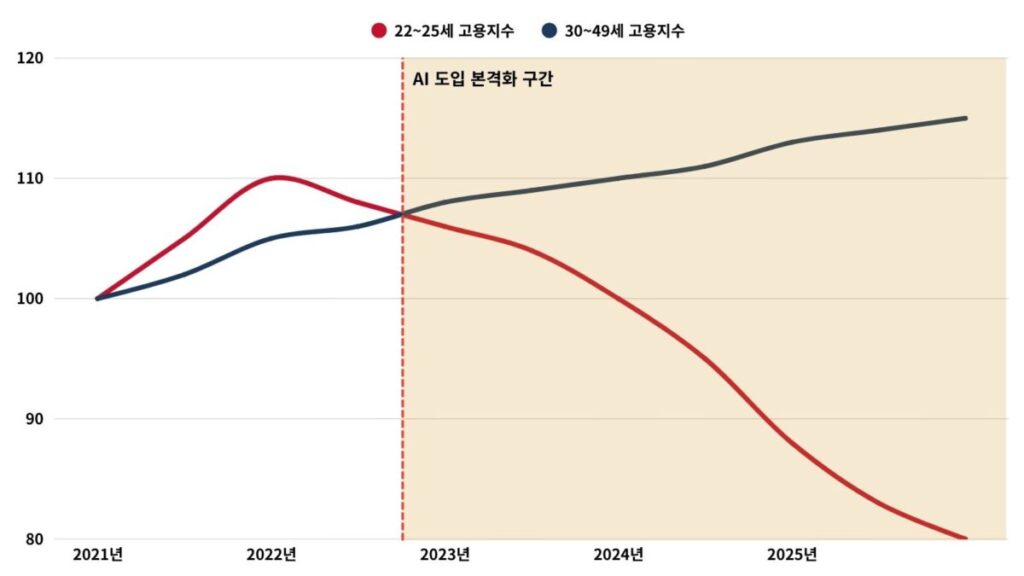
문제는 분배입니다.
미국의 22~25세 소프트웨어 개발자 고용은 2024년 대비 20% 가까이 감소한 반면, 같은 직군의 고령 개발자 고용은 오히려 늘었습니다.
AI 노출도 최상위 5분위 직업군에서 청년 고용은 최하위 5분위 대비 약 16% 감소했고, 격차는 2024년 중반부터 꾸준히 벌어지고 있습니다.
브린욜프슨 등(2025)은 이를 ‘탄광의 카나리아’라고 불렀습니다.
AI가 주니어 노동을 대체하면서 시니어 역할은 온존시키는 ‘경력편향 기술변화(seniority-biased technological change)’가 진행 중이라는 가설입니다.
기업 측의 기대도 같은 방향을 가리킵니다.
맥킨지 조사 대상 조직의 3분의 1이 향후 1년간 AI로 인한 인력 감축을 예상하며, 10억 달러 이상 매출 기업에서는 이 비율이 35%로 높아집니다.
감축 예상이 가장 큰 분야는 서비스 운영, 공급망·재고 관리, 마케팅·영업, 소프트웨어 엔지니어링 순입니다.
동시에 직업 구성 자체의 변화 속도는 PC·인터넷 도입기보다 빠릅니다.
생성형 AI 도입 이후 미국의 직업 믹스 변화 속도가 이전 두 기술 도입기의 변화 속도를 상회한다는 연구 결과가 나왔습니다.
놀라운 점은 노동자들이 자동화에 반드시 저항하지는 않는다는 것입니다.
844개 직업 과제를 조사한 연구에서 근로자의 46.1%가 해당 과제에 대해 AI가 대체해 주기를 적극 원한다고 답했습니다.
반복적이고 저부가가치인 일이 사라지면 고부가가치 일에 시간을 쓸 수 있다는 기대입니다.
그러나 ‘원하는 것’과 ‘실제 일어나는 것’이 같지 않다는 점은 청년 개발자 고용 수치가 이미 증언하고 있습니다.
AI for Science – 워크플로우 대체로의 전환
과학 영역에서 2025년의 변곡점은 ‘AI가 연구 단계를 가속하는 단계’에서 ‘워크플로우 전체를 대체하는 단계’로 넘어갔다는 것입니다.
자연과학 전반에서 AI 관련 논문 출판이 8만 150건에 이르며 전년 대비 26% 증가했고, 지구과학 8.8%·자연과학 전체 6.8%·생명과학 6.5%·물리과학 5.8%로 AI 침투율이 빠르게 상승 중입니다.
상징적 사례로 Aardvark Weather는 전통적 수치예보 파이프라인 전체를 단일 머신러닝 시스템으로 대체했고, FourCastNet 3는 60일 글로벌 기상예보를 4분 이내에 생성해 기존 기법 대비 8~60배 속도를 구현했습니다.
단백질 분야에서는 1억 1,100만 파라미터의 MSAPairformer가 ProteinGym 벤치마크에서 기존 선도 모델들을 앞섰고, 유전체학의 2억 파라미터 GPN-Star는 200배 큰 400억 파라미터 모델을 능가했습니다.
‘규모=성능’ 법칙이 과학 영역에서 예외를 보이기 시작한 것입니다.
그러나 한계도 분명합니다.
ChemBench에서 최상위 모델은 2,700개 이상 문항의 화학자 평균을 넘겼지만, ReplicationBench 천체물리 논문 재현 과제에서는 20% 미만의 점수에 그쳤습니다.
PaperArena에서 최상위 에이전트 정확도는 38.8%로 PhD 전문가 83.5%의 절반에도 미치지 못합니다.
‘가설 생성은 값싸졌지만 실험 검증은 여전히 비싸다.’ 이 비대칭이 과학 영역 AI 보급의 속도 제한 요인입니다.
AI for Medicine – 파일럿에서 광범위 배치로
의료는 2025년에 파일럿 단계에서 본격 배치로 넘어간 대표 분야입니다.
환자 진료 대화를 자동으로 임상 노트로 변환하는 앰비언트 AI 스크라이브가 복수의 대형 병원 시스템에서 채택되며, 한 병원은 의사 문서작성 시간이 최대 83% 감소했다고 보고했습니다.
같은 시스템에서 투자수익률(ROI)은 112%로 측정됐고, 번아웃 감소와 의료진 만족도 향상이 동반됐습니다.
2025년 FDA는 AI 의료기기 258건을 인증했습니다.
그러나 대부분은 신규 임상시험을 요구하지 않는 기기 수정 경로(510(k))였고, 무작위 대조 임상시험(RCT) 데이터로 뒷받침된 기기는 단 2.4%에 불과합니다.
진단 성능에서는 Microsoft의 AI Diagnostic Orchestrator와 OpenAI o3 조합이 문헌 출처 고난도 증례에서 85.5% 점수를 기록했고, 같은 조건에서 일반 도구 없이 진료하는 의사 점수는 20%에 머물렀습니다.
건강 관련 구글 검색의 84~92%가 AI 생성 요약을 상단에 노출합니다.
의사의 진단 프로세스와 환자의 정보 탐색 프로세스 양쪽 모두에서 AI가 전진 배치된 것입니다.
이 분야의 핵심 긴장은 ‘도입 속도’와 ‘근거 기반’의 분리입니다.
500건 이상의 임상 AI 연구 검토 결과 약 절반이 실제 환자 데이터가 아닌 시험형 질문에 의존했고, 실제 임상 데이터를 쓴 연구는 5%에 그쳤습니다.
한편 150명 당뇨 환자 무작위 시험에서 ‘디지털 트윈’ 기반 개입을 받은 환자의 71%가 1년간 건강한 혈당 수치 달성과 약물 감량에 성공하며 희망적 시그널도 나옵니다.
책임 AI – 사고는 급증, 투명성은 후퇴
능력 가속의 이면에는 안전 공백이 있습니다.
AI Incident Database에 등록된 사고 건수는 2024년 233건에서 2025년 362건으로 55% 증가했습니다.
OECD AI Incident Monitor 기준으로는 2026년 1월 한 달에만 435건이 기록됐습니다.
반면 주요 프론티어 개발사 대부분은 MMLU·SWE-bench 같은 능력 벤치마크 결과는 공개하되 BBQ·HarmBench·SimpleQA 같은 책임 AI 벤치마크 결과는 좀처럼 보고하지 않습니다.
측정되는 것만 관리되는 ‘측정 편향’이 구조화되고 있습니다.
투명성 지표도 후퇴했습니다.
Foundation Model Transparency Index 평균 점수는 2023년 37에서 2024년 58로 상승했다가 2025년 40으로 재하락했습니다.
특히 훈련 데이터·연산 자원·배포 후 영향 공개가 취약해졌습니다.
모델이 가장 강력해지는 구간에서 가장 불투명해지는 역설입니다.
환각 문제도 새로운 정확성 벤치마크에서 심각하게 드러났습니다.
상위 26개 모델의 환각률이 22%에서 94%까지 분포했고, GPT-4o는 98.2% 정확도에서 64.4%로, DeepSeek R1은 90% 이상에서 14.4%로 급락했습니다.
특히 거짓 진술을 ‘타인의 믿음’으로 제시하면 모델이 잘 처리하지만, ‘사용자 본인의 믿음’으로 제시하면 성능이 붕괴했습니다.
대화 맥락 조작에 대한 근본적 취약성입니다.
최근 실증연구는 안전성을 개선하는 훈련 기법이 정확성을 저하시키는 등 책임 AI 차원들 사이의 트레이드오프가 원리적으로 존재함을 보여줍니다.
교육의 지연과 인재 파이프라인의 이상 신호
교육에서는 사용은 폭증하는데 제도는 공백인 상태가 심화되고 있습니다.
미국 고등학생·대학생의 80% 이상이 과제에 AI를 사용하지만 중·고등학교 절반만 AI 정책을 보유하고, 교사 중 정책이 명확하다고 답한 비율은 6%에 불과합니다.
국가 단위에서는 중국과 아랍에미리트가 2025~26학년도부터 초·중등 AI 교육을 국가 수준에서 의무화했습니다.
고등교육에서 예상 밖의 신호가 포착됩니다.
미국 4년제 대학의 컴퓨터공학(CS) 학부 전공 등록이 2024~2025년 사이 11% 감소했습니다.
같은 시기 청년 소프트웨어 개발자 고용 감소와 맞물리며 ‘CS 진입의 저온 현상’이 나타난 셈입니다.
반대로 AI 소프트웨어 관련 석사 졸업생 수는 2023~2024년 17% 증가했고, 2022~2024년 누적 82%나 늘었습니다.
신규 AI 박사 수도 2022~2024년 사이 22% 증가했으나 그 증가분이 모두 학계 취업으로 향하며 지난 10년간 이어진 ‘박사의 산업계 이동’ 경향을 역전시켰습니다.
여기에 하나 더 결정적인 숫자가 붙습니다.
2017년 이후 미국으로 이주하는 AI 연구자·개발자 수가 89% 감소했고, 이 중 80%가 최근 1년간의 감소분입니다.
미국은 여전히 최대 AI 인재 보유국이지만 10년 넘게 최저 수준의 신규 유입률을 기록 중입니다.
인재 유입 없이 자본만 쌓이는 상태가 지속된다면 미국 AI 생태계의 장기 재생산 기반이 흔들릴 수 있다는 경고입니다.
AI 주권의 부상과 규제 방향의 분화
2025년 국가 AI 전략 채택의 절반 이상이 개발도상국에서 나왔습니다.
사하라 이남 아프리카·중앙아시아·중동 국가들이 처음으로 AI 정책 영역에 진입했고 2025년 추가 전략 개발이 진행 중입니다.
‘국내 AI 역량에 대한 통제력 확보’를 뜻하는 AI 주권(AI sovereignty)이 국가 정책의 조직 원리로 부상했습니다.
그러나 이를 뒷받침할 인프라는 지역 간 격차가 극심합니다.
2018~2025년 유럽·중앙아시아의 국가 지원 AI 슈퍼컴퓨팅 클러스터는 3개에서 44개로 확대됐지만, 남아시아·중남미·중동북아프리카는 각각 2·3·8개 수준에 머물고 있습니다.
선언된 주권과 실제 역량의 괴리입니다.
규제 방향은 분기 중입니다.
EU AI Act의 1차 금지 조항이 2025년 2월 발효된 반면, 미국은 1월 ‘Removing Barriers to American Leadership in AI’ 행정명령으로 규제 완화 방향으로 선회했습니다.
일본·한국·이탈리아가 2025년에 각각 국가 수준 AI 법률을 통과시키며 ‘EU 규제 중심과 미국 혁신 중심 사이의 제3의 길’을 모색하고 있습니다.
데이터 주권 접근도 지역별로 상이합니다.
2024년까지 동아시아·태평양 77건, 사하라 이남 아프리카 71건, 유럽·중앙아시아 66건의 데이터 지역화 조치가 나왔지만 북미는 단 3건입니다.
미국 내부에서는 의회 AI 관련 증인이 2017년 5명에서 2025년 102명으로 20배 증가했습니다.
그중 산업계 비중이 13%에서 37%로 올라가며 최대 집단으로 부상한 반면 학계 비중은 15%로 하락했습니다.
2013~2024년 미국 AI 관련 공공 계약·보조금 누적액이 약 204억 달러인 반면 2025년 한 해 민간 투자만 2,859억 달러입니다.
한 자릿수 대 세 자릿수의 격차 속에서 AI 정책 담론의 중심이 산업계로 이동하고 있습니다.
여론의 양가성과 50%포인트 전문가-대중 격차
AI에 대한 대중 인식은 복잡합니다.
‘AI 제품·서비스의 이점이 단점보다 크다’는 응답이 2024년 55%에서 2025년 59%로 올라갔지만 ‘불안하다’는 응답도 52%로 동반 상승했습니다.
낙관과 불안의 동시 증가는 양가적 감정 구조를 시사합니다.
지역별 편차도 큽니다.
중국·말레이시아·태국·인도네시아·싱가포르에서는 80% 이상이 AI가 3~5년 내 삶을 근본적으로 바꿀 것으로 기대하는 반면, 인도는 2024~2025년 AI 우려 응답이 14%포인트 뛰며 조사 대상국 중 가장 큰 증가폭을 기록했습니다.
가장 주목할 격차는 전문가와 대중 사이에 있습니다.
‘AI가 업무에 긍정적 영향을 줄 것’이라는 전망은 전문가 73% 대 대중 23%로 50%포인트 격차입니다.
경제 영향(전문가 69% 대 대중 21%), 의료 영향(전문가 84% 대 대중 44%)에서도 체계적 차이가 반복됩니다.
미국인 64%는 향후 20년간 AI로 일자리가 감소할 것으로 예상하고 증가 전망은 5%에 그칩니다.
규제 역량에 대한 신뢰도도 파편화되고 있습니다.
미국 응답자가 자국 정부의 AI 규제 역량을 신뢰하는 비율은 31%로 조사 대상 중 최저였고 글로벌 평균 54%를 크게 밑돕니다.
반면 EU의 AI 규제 역량에 대한 신뢰도는 중앙값 53%로 미국(37%)·중국(27%)을 모두 상회합니다.
국내 거버넌스 신뢰는 낮지만 초국적 거버넌스 신뢰가 상대적으로 높다는 이 역전 현상은 향후 AI 규제 경쟁에서 중요한 정당성 기반이 될 수 있습니다.
환경 비용 – 능력과 함께 확장되는 물리적 발자국
AI Index 2026 · Environmental footprint
디지털 비용이 실물 예산을 소모하는 전환
AI 능력 확장이 전력·물·탄소라는 물리적 자원을 소비하기 시작했다
전력
29.6GW
AI 데이터센터 전력 용량
= 뉴욕주 최대 전력 수요
전력망 부담의 한계 영역 접근
물
1,200만 명
GPT-4o 연간 물 사용 환산
= 1,200만 명 식수 수요 초과 가능성
냉각수가 지역 물 스트레스 가중
탄소
72,816톤
Grok 4 훈련 CO₂ 배출량
= 중소 도시 연간 배출 수준
모델 한 건 훈련의 환경 비용
연산 용량 성장률
연 3.3배
2022년 이후 매년 · 2025년 H100 환산 1,710만 유닛
엔비디아 연산 점유율
60%이상
전 세계 AI 연산의 절반 이상
데이터: Stanford HAI AI Index 2026, Chapter 1 (Environmental Impact) · 시각화: econo-log
보고서가 새롭게 조명한 축은 환경 비용입니다.
2025년 출시된 Grok 4의 추정 훈련 배출량은 약 72,816톤 CO2 등가로 중소 도시의 연간 배출과 맞먹는 수준입니다.
AI 데이터센터 전력 용량은 29.6기가와트에 도달해 뉴욕주 최대 수요와 유사한 규모로 전력망 부담의 한계 영역에 접근했습니다.
GPT-4o 추론 단일 모델의 연간 물 사용량이 1,200만 명의 식수 수요를 초과할 가능성이 있다는 추정도 나왔습니다.
냉각수 수요는 지역 물 스트레스를 가중시킵니다.
즉, AI의 능력 확장은 디지털 비용으로만 끝나지 않습니다.
전력·탄소·물이라는 실물 예산을 소모합니다.
이 제약은 이미 데이터센터 입지 선정, 전력망 투자 계획, 지역 물 배분 정책에 영향을 미치기 시작했습니다.
향후 2~3년 안에 ‘연산 용량 증설을 하고 싶어도 전력이 없어서 못 한다’는 구조적 병목이 본격화할 가능성이 높습니다.
여기까지가 원문 해설 – 이제 한국의 관점에서 다시 읽기
지금까지가 AI Index 2026의 주요 주장·근거·데이터 해설입니다.
이 보고서는 직접적으로 한국을 다루지 않지만, 담긴 숫자들을 한국의 위치에 겹쳐보면 몇 가지 구조적 의제가 뚜렷해집니다.
한국은 ‘소량 정밀 생산국’ 포지션 – 양 대신 밀도로 버티는 전략의 유효성
한국은 AI 특허 건수 1인당 세계 1위, 모델 생산 5건(미국 50건·중국 30건 대비), 민간 AI 투자 17억 8천만 달러(15위권), AI 인재 집중도 1.25%(13위권), AI 구인 비중 최근 1년간 4.8%포인트 상승(조사 대상 중 최대 증가폭)이라는 수치 조합을 보입니다.
규모의 전쟁에서는 미·중에 명백히 밀리지만 밀도·효율·특정 영역 집약도에서는 세계 상위권을 지키는 형태입니다.
이는 반도체·배터리에서 한국이 보여 온 경로와 유사합니다.
‘범용 플랫폼 주도국’이 되기 어려운 조건에서 ‘특정 층위의 결정적 부품·공정·응용’에서 경쟁력을 응축하는 전략입니다.
문제는 이 전략의 지속 조건이 점점 까다로워진다는 점입니다.
보고서가 거듭 보여주듯 경쟁의 축이 모델 성능에서 물리적 인프라와 에너지·데이터센터·전력망으로 이동하고 있습니다.
한국은 국토 면적 대비 데이터센터 집적도가 이미 높고 수도권 전력망 포화가 현실 의제로 들어와 있습니다.
원전·재생에너지 배합, 동남권·호남권 분산 데이터센터 입지, 수자원 가용성 등이 AI 경쟁력의 함수가 되는 국면입니다.
‘소량 정밀’ 전략을 유지하려면 반도체 공급망뿐 아니라 전력·용수·토지 인프라의 전략적 배분이 함께 관리돼야 합니다.
청년 개발자 20% 고용 감소는 한국에 먼저 또는 나중에 올 것인가
보고서가 가장 강력하게 증언한 노동시장 신호 중 하나는 미국 22~25세 소프트웨어 개발자 고용의 20% 감소입니다.
한국은 미국보다 AI 채택률이 낮다는 표면적 이유로 이 충격이 늦게 올 것이라는 관측이 가능합니다.
그러나 반대의 시나리오도 설득력이 있습니다.
한국 개발자 시장은 미국보다 규모가 작고 신규 공급이 적으며 기업의 구조조정 반응 속도가 빠른 편입니다.
대기업·중견 SI 업종의 코딩 자동화 도입이 본격화되면 청년 공급 비율이 높은 시장 특성상 연령별 충격이 더 가파르게 나타날 여지가 있습니다.
여기에 한국의 CS 진학 인구 구조를 겹치면 의제가 분명해집니다.
미국에서 이미 2024~2025년 CS 학부 등록이 11% 감소했고 AI 석사가 17% 증가했습니다.
한국도 같은 분화가 일어날 가능성이 있습니다.
학부의 범용 CS 수요가 줄고 AI·데이터·MLOps 특화 석사 수요가 늘어나는 구조입니다.
이 경우 정부와 대학의 대응은 ‘CS 학부 증원’이 아니라 ‘학부 교육 내용의 AI 중심 재설계 + 석박사 특화 트랙의 조기 확충’이 되어야 정합적입니다.
단순히 입학 정원을 늘리는 방식은 이미 미국에서 관찰된 패턴과 반대로 가는 정책이 됩니다.
일본·한국·이탈리아의 AI 국가법 – 제3의 길의 실효성이 시험대
보고서는 EU 규제 중심과 미국 혁신 중심 사이에서 일본·한국·이탈리아가 2025년에 각각 국가 수준 AI 법률을 통과시켰다는 사실을 명시하고 이를 ‘제3의 길’로 주목합니다.
이 세 나라의 공통점은 자체 AI 생태계를 갖고 있되 규모가 미·중만큼 크지 않아, 규제 아비트라지(차익)의 손익 계산을 해야 한다는 점입니다.
너무 강한 규제는 자국 기업의 국제 경쟁력을 깎고, 너무 약한 규제는 해외 모델에 대한 주권을 잃습니다.
향후 2~3년이 ‘제3의 길’이 실효성을 입증하는지, 아니면 EU 모델로 수렴하는지가 판가름나는 시기가 될 가능성이 높습니다.
한국 정책 담당자 입장에서는 자국법의 시행령 세부 설계와 일본·이탈리아와의 운영 경험 교환이 실질적으로 중요한 과제가 됩니다.
투자 23배 격차의 진짜 의미 – 한국 기업의 선택지
미국과 중국의 민간 AI 투자 격차가 23배라는 수치는 표면적으로는 중국에 불리한 지표로 보입니다.
그러나 중국 정부 유도 자금이 2000~2023년 1,840억 달러에 이른다는 점을 감안하면 격차는 많이 좁혀집니다.
한국 기업과 투자자가 여기서 읽어야 할 메시지는 ‘미국 AI 생태계는 자본 집중도가 압도적’이라는 사실과 ‘중국 AI는 민간 자본만으로 측정하면 과소평가된다’는 사실의 동시 인식입니다.
미국 시장 투자(캘리포니아 한 주에 2,180억 달러 집중)는 여전히 매력적이지만 밸류에이션이 고도로 수렴된 상태이고, 중국 시장 투자는 수치로 보이지 않는 정부 자금의 존재가 기회이자 리스크입니다.
한국 스타트업 입장에서 보면 글로벌 10억 달러 이상 펀딩 이벤트가 2024년 15건에서 2025년 28건으로 거의 두 배가 된 반면 평균 투자 규모가 46% 증가한 구조가 핵심입니다.
돈은 더 많이 풀리지만 더 소수의 딜에 집중됩니다.
‘적당히 좋은 기업’은 조달이 어려워지고 ‘압도적 포지션을 확보한 소수’에 자본이 쏠리는 양극화입니다.
한국 AI 스타트업에는 ‘초기 투자 문턱이 낮아지는 기회’가 아니라 ‘중기 투자 문턱이 더 높아지는 리스크’로 해석되는 것이 타당합니다.
소비자 잉여 1,720억 달러 – 한국에서 가장 먼저 주목해야 할 수치
이 보고서에서 가장 간과되기 쉽지만 가장 경제학적으로 강력한 수치는 미국 소비자 잉여 1,720억 달러입니다.
1년 새 54% 증가, 1인당 중위값 3배 증가라는 속도는 GDP 통계가 포착하지 못하는 생산성 혁명이 이미 일어났음을 시사합니다.
한국도 생성형 AI 사용률이 빠르게 올라가고 있으므로 유사한 소비자 잉여 급증이 진행 중일 가능성이 매우 높습니다.
정책 관점에서 이 수치의 함의는 두 가지입니다.
첫째, 공식 경제지표만 보는 경기 판단은 AI 도입의 실질 효과를 체계적으로 과소평가할 위험이 있습니다.
통계청·한국은행 차원에서 ‘AI 활용에 따른 소비자 잉여’ 추정 방법론을 도입할 시점이 된 것으로 보입니다.
둘째, AI 서비스의 ‘무료 제공’ 모델이 GDP에 잡히지 않는다는 것은 법인세·부가세 기반 재정 시스템이 AI 시대의 실질 후생을 제대로 포착하지 못하게 된다는 의미입니다.
디지털세·AI 과세 논의가 단순한 분배 의제가 아니라 재정 구조의 지속가능성 문제로 확장될 수 있는 이유입니다.
결국 이 보고서가 말하는 것
AI Index 2026의 최종 메시지는 데이터가 한 방향을 가리키지 않는다는 점입니다.
능력은 가속되지만 평가·거버넌스·교육이 지연됩니다.
투자는 사상 최대치를 경신하지만 수혜는 소수 기업·소수 지역·소수 인구집단에 집중됩니다.
대중화는 완료됐지만 그 가치의 상당 부분이 공식 지표에서 측정되지 않습니다.
국가들이 AI 주권을 선언하지만 실제 역량은 여전히 미·중 양극에 편중됩니다.
이런 국면에서 가장 중요한 감각은 ‘한 방향 기대를 접는 것’이라고 판단됩니다.
AI로 모든 것이 좋아질 것이라는 기대도, AI가 모든 일자리를 없앨 것이라는 공포도 데이터와 맞지 않습니다.
같은 기술이 같은 직업 안에서 생산성 이득과 진입 장벽을 동시에 만들고 있고, 같은 국가 안에서 혁신과 규제 공백을 동시에 키우고 있습니다.
경제 주체가 취할 전략은 ‘업종 내 이원화’를 전제로 한 적응입니다.
어떤 기술이 중요한지에 대한 답만큼이나 ‘그 기술이 내 업무 안에서 무엇을 대체하고 무엇을 증강하는지’를 구체적으로 파악하는 작업이 점점 더 중요해질 것으로 보입니다.
규모의 열위, 밀도의 우위 – 한국의 AI 포지션
세계 순위
1위
1인당 AI 특허 건수
집약적 혁신 생태계의 밀도 지표
세계 순위
18위
개인 AI 채택률 30.7%
전년 대비 +4.8%p, 조사국 중 최대 증가폭
세계 순위
12위
민간 AI 투자 17.8억 달러
미국의 1/160 규모 — 양적 경쟁의 한계
네 가지 전략 과제
과제 01 · 인프라 재배분
전력·용수·토지가 AI 경쟁력 함수
수도권 전력망 포화와 데이터센터 집적도 상승이 ‘소량 정밀 전략’의 지속 가능성 저해.
→ 원전·재생에너지 배합, 분산 데이터센터 입지 설계
과제 02 · 인재 파이프라인
CS 학부 증원이 아닌 재설계의 시점
미국 CS 학부는 -11%, AI 석사는 +17%. 한국도 학부 교육의 AI 중심 재편과 석박사 트랙 확충이 정합적.
→ 청년 개발자 -20% 고용 충격의 선행 대응
과제 03 · 제3의 길 검증
한국 AI 기본법 시행령 시험대
EU 규제 중심과 미국 혁신 중심 사이, 일본·이탈리아와 함께 ‘제3의 길’의 실효성이 2~3년 내 판가름날 것.
→ 시행령 세부 설계와 운영 경험 공유의 실무 의제
과제 04 · 측정되지 않는 가치
소비자 잉여 1,720억 달러는 GDP에 없음
AI 서비스의 무료 제공이 법인세·부가세 기반 재정 시스템에 균열. 공식 지표가 실질 후생을 놓침.
→ 소비자 잉여 추정 방법론·디지털세 논의 확장
데이터: Stanford HAI AI Index 2026 · 해석·시각화: econo-log